Abstract
The development of large language models (LLMs) has greatly advanced the field of multimodal understanding, leading to the emergence of large multimodal models (LMMs). In order to enhance the level of visual comprehension, recent studies have equipped LMMs with region-level understanding capabilities by representing object bounding box coordinates as a series of text sequences (pixel2seq). In this paper, we introduce a novel paradigm for object location modeling called pixel2emb method, where we ask the LMM to output the location embeddings and then decoded by different decoders. This paradigm allows for different location formats (such as bounding boxes and masks) to be used in multimodal conversations. Furthermore, this kind of embedding based location modeling enables the utilization of existing practices in localization tasks, such as detection and segmentation. In scenarios with limited resources, our pixel2emb demonstrates superior performance compared to existing state-of-the-art (SOTA) approaches in both the location input and output tasks under fair comparison. Leveraging the proposed pixel2emb method, we train an LMM named NExT-Chat and demonstrate its capability of handling multiple tasks like visual grounding, region caption, and grounded reasoning.
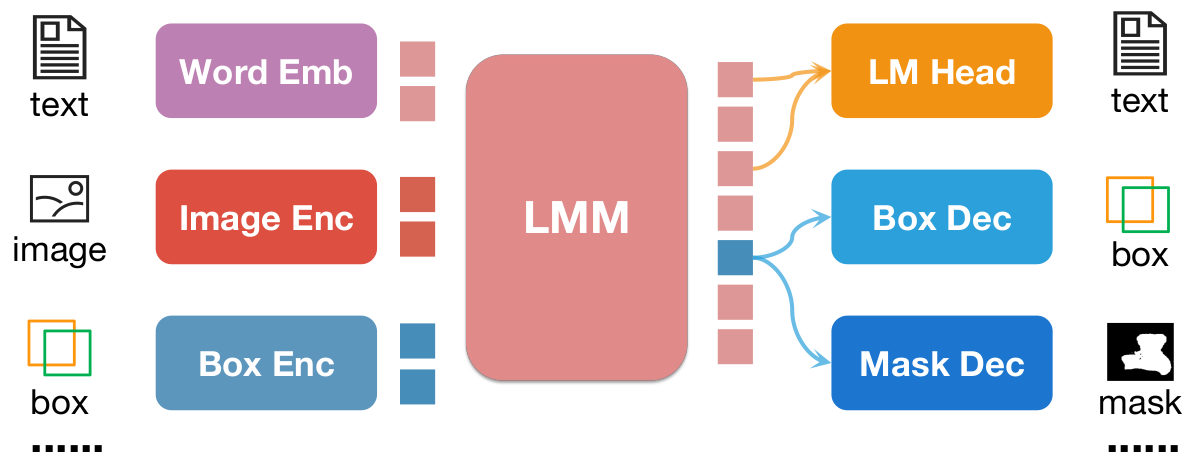
Pixel2Emb Framework
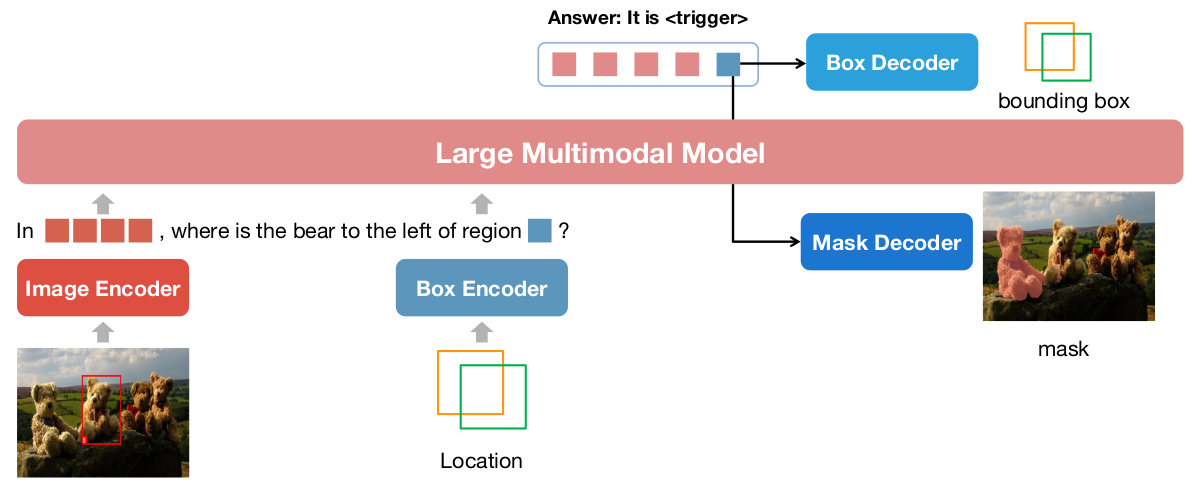
Experiments
Referring Expression Segmentation (RES)
Referring Expression Comprehension (REC)
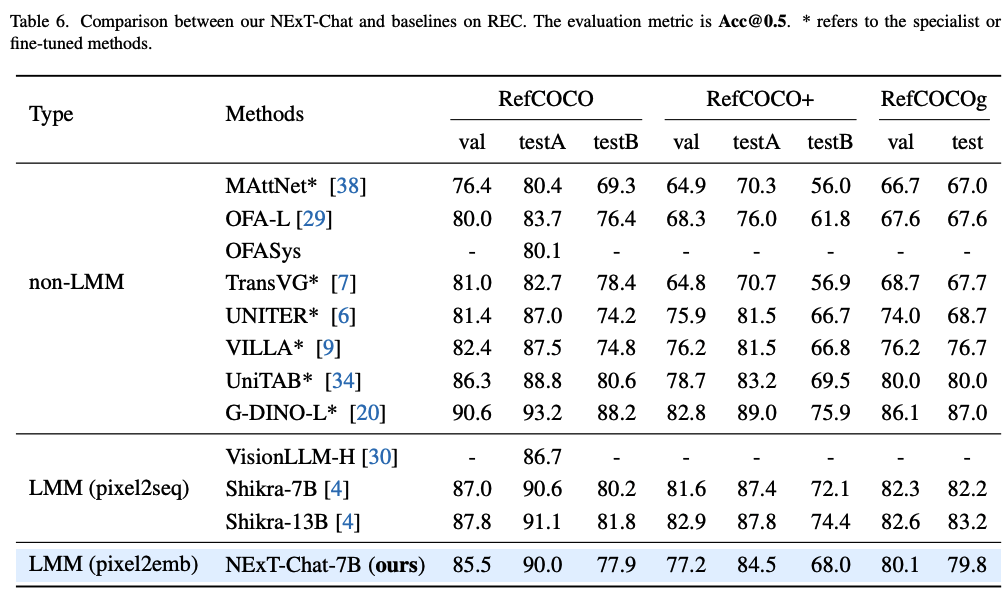
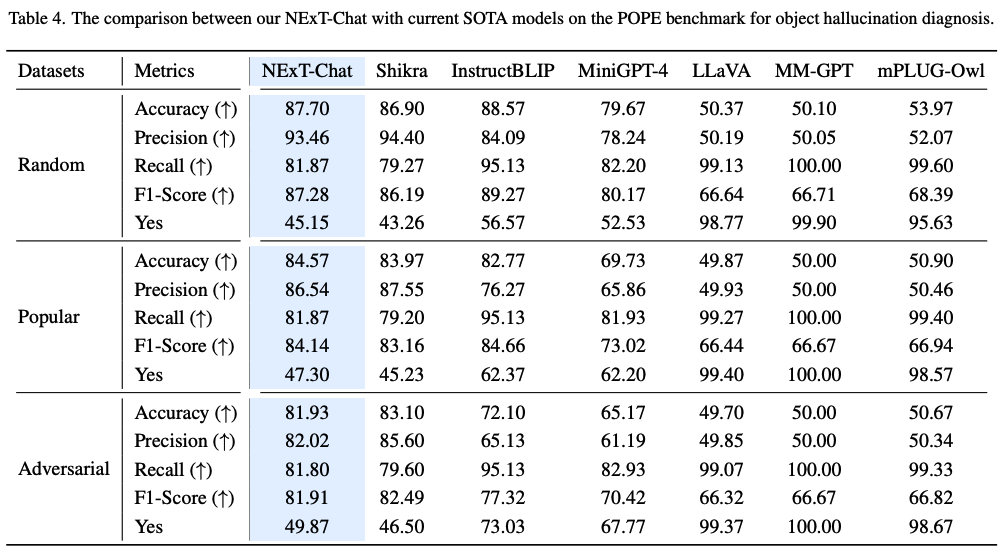
Image-level Hallucination Evaluation (POPE)
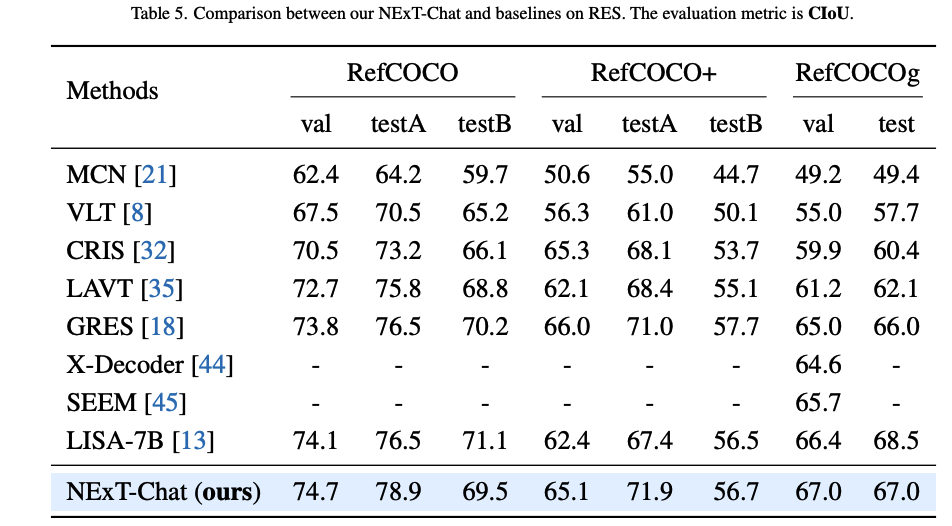
Region Caption (RefCOCOg-val)